Geo-Redundancy for MySQL InnoDB And NDB Clusters
 admin
admin- posted on
- 5 Comments
MySQL highly available solutions, InnoDB Cluster (it uses InnoDB storage engine and is based on Group Replication plugin) and NDB Cluster (NDB storage engine), offer high scalability and redundant topologies.
- InnoDB Cluster can be configured with up to 9 replicas, in single primary configuration or multi-primary.
- NDB Cluster instead, while being a much different solution, offers the chance to have up to 4 data nodes replicated for a single shard of data (or node group) and up to a total number of 144 nodes.
Redundancy ensures that multiple copies of data exist and are available transparently to the client. That prevents service disruption and lowers the risks of data loss caused by hardware malfunctioning. But this is not still enough in case of full data center outage or natural disasters. That’s when it is sometimes needed to design geographically redundant solutions. Several options are possible.
InnoDB Cluster to standalone MySQL Server
This architecture requires minimal maintenance.
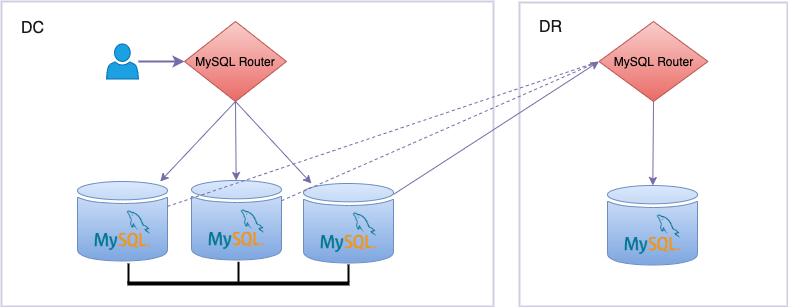
- InnoDB Cluster is deployed normally in DC, clients access through MySQL Router
- Disaster Recovery (DR) site hosts a MySQL Server and a MySQL Router instance bootstrapped against the InnoDB Cluster in DC.
- MySQL Server instance in DR is a classical asynchronous replica configured with CHANGE MASTER TO, but selecting as source MySQL Router’s R/W IP and port.
This solution requires little maintenance: MySQL Router will fetch events from the primary instance in the primary cluster and will deal with primary instance issues (crash, network isolation, primary role assigned to other instance), thus selecting a good source of data, transparently. Replica in DR will be updated at any moment (minus events not replicated because of replication lag, this is asynchronous replication, best option to replicate data across high latency sites or regions, but subject to the effects of latency).
Starting from MySQL Server 8.0.23, it is possible to obtain automated failover of DR instance to the correct primary instance in the DC cluster using asynchronous connection failover mechanism, which in this version also supports Group Replication topologies. This means that it is possible to get rid of MySQL Router on the DR side and achieve failover to another cluster instance in the DC side, thus simplifying the architecture.
Group Replication to Group Replication
This solution is based on Group Replication, the core of InnoDB Cluster. Two clusters are deployed in the two sites and synchronised via the traditional asynchronous replication channel.

- One DR cluster instance can be configured as replica (CHANGE MASTER TO) but it must be the primary instance: only primary instances can accept writes and introduce them into the cluster (in case of DR multi-primary instance, any instance can be chosen as replica).
- This architecture needs manual maintenance if any of the instances chosen as source and replica fail. If DC source fails, DR replica must reconfigure it. If DR replica fails, new DR primary must be reconfigured against the source.
- Compared to previous DR standalone solution, clients can point to DR cluster without any expected degradation, especially for what concerns distributed reads.
- MySQL Router cannot be used with Group Replication, because MySQL Router relies on cluster metadata (which is the main difference between InnoDB Cluster and Group Replication).
- InnoDB Cluster stores local metadata schema, which is a local cluster characteristic. For this reason, to preserve local metadata from being overwritten and corrupted by the replication channel, replication between InnoDB Clusters is not possible.
InnoDB Cluster stretched across data centers
It is also possible to prevent catastrophic failures with the standard InnoDB Cluster deploying every instance in a data center.

This approach, the simplest possible, is sensitive to latency between the data centers. Every distributed system requires low latency, preferably single digit ms latency between the data centers/ sites, and a stable connection, otherwise this will generate a poor response and a degradation of the service. Nowadays cloud providers offer acceptable latency between data centers in same site, and also good latency across data centers in the same geographic area (though latency between regions is unacceptable).
NDB Cluster to NDB Cluster
I have shown several options using InnoDB Cluster, now I will briefly introduce NDB Cluster geographic redundancy. NDB Cluster supports replicating clusters via the traditional MySQL Servers (also known as SQL nodes, said in NDB Cluster terminology).

- Replication model requires minimum one (recommended two, as in the picture) SQL node per cluster per site, forming part of the respective cluster.
- In DC, every SQL node has binary logging enabled and subscribes to changes in the NDB data nodes.
- In DR, one SQL node is configured as replica of one source SQL node in DC, hence replicates events and apply them to NDB storage engine.
- This architecture envisions a pair of replication channels, one active at time, to prevent loss of events if the binlogging SQL node fails or is disconnected from the cluster. Failover of replication channels must be executed manually.
If you have a different geo-redundancy setup, and you want to share, please comment this post.




Geo-Redundancy for MySQL InnoDB And NDB Clusters
[…] post Geo-Redundancy for MySQL InnoDB And NDB Clusters appeared first on […]
Rajesh Bansal
Hi , I need your support to prepare a mysql geo redundant site design. I have 1 site with 2 master-master nodes with mysql 5.1 installed. Now need to propose geo-redundant setup. Can you help me. I am ok with genuine commercials also.
admin
If you wish to use the commercial build you need to contact MySQL Sales and Sales will let you know how you can get assistance from the MySQL Support team. You can contact a MySQL Sales Rep. here:
https://www.mysql.com/about/contact/
If you wish to use the Community build, then you can get to the MySQL forums: https://forums.mysql.com/ and have the MySQL Community assist, but quick support is not guaranteed.
Josh
Hi,
The article is very nice, thank you for sharing it!
In the proposed architecture (InnoDB Cluster to standalone MySQL Server) the instance in DR is read-only or whether we can configure it as read-write? If it’s read-only in the event of DC failure is it possible to make it R/W without much effort?
admin
Hello, and thanks for reading this post. Yes, you can promote the replica in DR to be the principal workload endpoint by making it R/W, as in the case of standard replication failover use case.
https://dev.mysql.com/doc/refman/8.0/en/replication-solutions-switch.html
But then you will have to allow the DC site to be a replica of DR (pointing the *primary* instance in DC to the instance in DR, acting as primary) to keep sites consistent. Or, if you don’t plan to make DC a replica of DR, perform a point-in-time-recovery of DC to realign to DR once DC is viable again and before reconfiguring DC as the workload endpoint.